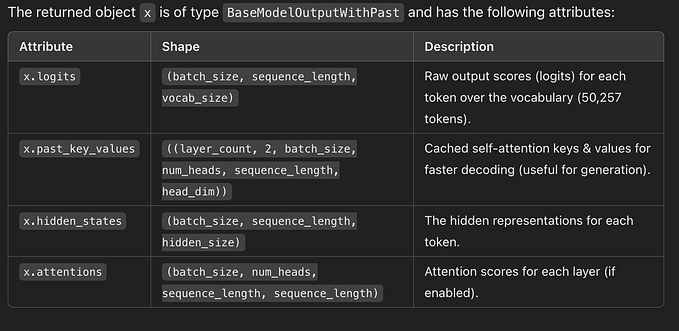
Quantization of notes
Frequency vs. time for 6 seconds of music shows some frequencies are held constant. Transition from Ma to Sa between 3–4 seconds hits 6 frequencies, inclusive of Ma and Sa. Three of the freqs are attributed to Ga, or komal ga. One is for Re. The transition from Ma to Sa is monotonic and the increments between notes is small, so it’s still discrete, i.e., quantized, but would sound more like a continuum than a step change from Ma to Sa.
Comparing relative duration of notes: in 0.5 seconds, we hear 6 frequencies. Where as Re is held constant for ~0.5 sec near the 1 sec time timestamp.

In tabular form:

P-D-N-S-R-G-M, M-G-R-S-N-D-P on a g-scale bamboo flute.

The flat region is one note. Any fluctuation in that is the magnitude of quivering or noise.
Transcription in Python
Nuances of code
- FFT output creates a list of frequencies in descending order.
- The highest frequency is not necessarily the note to be played, it’s just one of the harmonics.
- Choose the frequency with the most ‘prominence’
- Used a variable, t, later in the code, whereas t had been used to calculate t*, and t* is what I was thinking of. Maybe using RUST would decrease these problems.
- The time window for a FFT was set at 0.04 sec. So the first list of pitches is song length / time window. Consecutive notes that are the same are grouped together. Any note < xtime_window is dropped as noise. Dropping these rows means that again there are notes that are consecutive and it’s the same note. So again they are grouped together. Initally I didn’t realize that I would need to do this grouping twice to get the right duration of note.
- If I don’t keep track of prominence of the peak in autocorrelation, there is no amplitude or volume information. Is the volume information in the amplitude of the peaks in autocorrelation?
- How can the prominence data be explored more insightfully?
Why Transcribe
- The audio waveform has the complete information in digital form, so why transcribe into notes?
- The waveform is not human absorb-able / readable.
- This gets to thinking about other information that’s in a form which doesn’t cater to being grasped by humans. How to extract notes which can be understood.
- The way this problem is solved here is that information is chunked, and a frequency representing the chunk is noted. Frequency represents a pattern. Some information from the chunk is lost and this is accepted. ‘Frequency’ is not always the right characteristic to summarize a chunk of info. How can the right characteristic be identified?