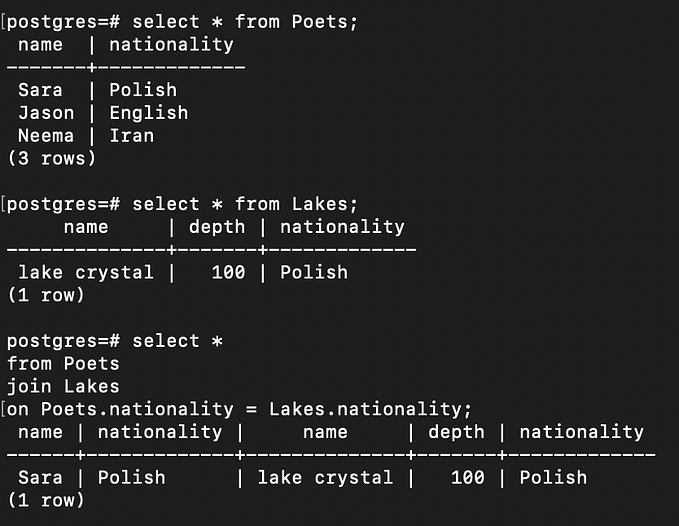
Models that modify Probability Distributions, I/O for Models via Web Protcols
LLMs are models that modify the probability distribution of a set of events, and predict the next event.
In this case, the event is the next token. The token can be a word or a subword.
The consideration around subwords allows us to account for vocabulary that is not in the original vocabulary list, allowing us to work with foreign words and proper nouns.
For the model named as GPT2LLMHead, the input can be a text phrase or a numerical list of token ids.
When the input is a list of token ids, the output, let’s call it x, has several attributes.

The logits are a probability distribution over every token that the model is trained on. Is a larger token size vocabulary brute forcing? Even if it's brute forcing, is it helpful? A larger token size means the probability distribution at each inference step is over more events, increase compute.

The number of total tokens used to train the LLM.
The maximum number of tokens in one forward pass.

ML Ops — Passing data to ML Models via internet protocols: http

import requests
# URL of a streaming or large audio file
audio_url = "https://sample-videos.com/audio/mp3/crowd-cheering.mp3"
response = requests.get(audio_url, stream=True)
# Save the streamed audio to a file
with open("streamed_audio.mp3", "wb") as f:
for chunk in response.iter_content(chunk_size=1024): # Process chunks of 1KB
if chunk:
f.write(chunk) # Save to file
print("Audio streaming complete. File saved as streamed_audio.mp3")Above snippet shows how to work with streaming data using the requests library.
Load Balancing Algorithms in NGINX

Passing data from web server to application server:
HTTP, text-based, to FASTCGI (or alternative), binary protocol

Another protocol: Memcached
To use Memcached, install the software, and then install the python client, i.e. python interface. Memcached has only a few methods: get, set, delete, increment a value up, decrease a value by 1, and a couple others.

grpc is an http/2 based protocol: