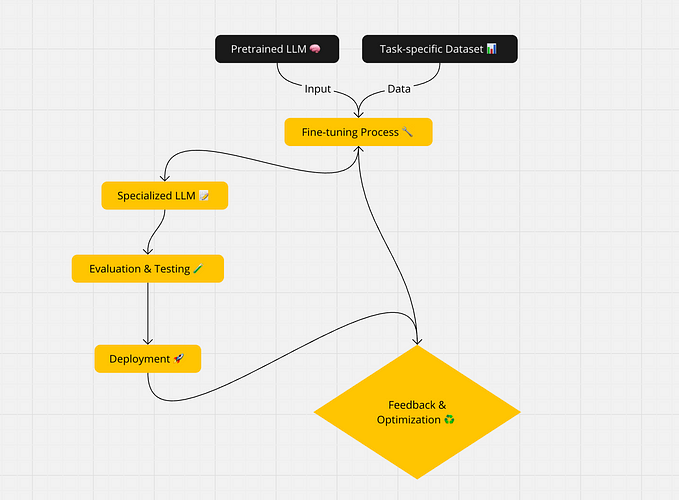
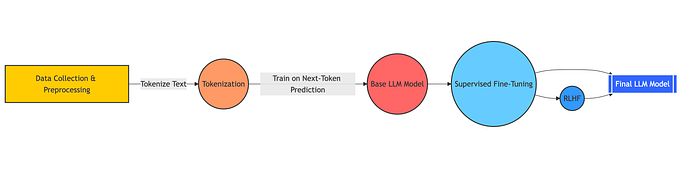
Fine Tuning Large Language Models
If the task is translation, we need paired text rows for training data. Something like this for English/Hindi.
Classification Noise
वर्गीकरण ध्वनि
Source Source Equipment
स्रोत उपकरण
Electric equipment
इलेक्ट्रिक उपकरण
with contacts Electric discharge
सम्पर्क सूची
Note the Hindi text here was generated using Machine translation so it might not be correct. I used the Helsinki en-hi model, hosted on hugging face, and anuvaad (pip install anuvaad).
To validate if a pairing is correct, we use Laser or Labse or Sonar (names of models).
These models are math functions that convert a text phrase to a vector. The dot product of two vectors is close to 1 if they represent semantically similar information.
This is true across languages. Two semantically similar English phrases are mapped to vectors where v1 · v2 ~ 1 and two semantically similar phrases, one in English, one in another language are also mapped to vectors where v1 · v2 ~ 1. (It’s incredible that such a vast amount of information can be converted to a representation that lends itself to this kind of computation.)
We need these rows of data because when models are trained, using supervised learning, they can’t take in a large piece of text: Washington Post and Le Monde. There is some token limit based on how the model is set up. The newspapers of two languages would have to be scraped into smaller phrases. When you split the text, phrase number 5 in English could be the translation for phrase #6 in French.
The models above help us align, here is an example where text was correctly aligned for English-Hindi. All 3 phrases are programmatically extracted from a technical manual.
GOOD:
English Phrase
Hindi Phrase by Default
Model suggested Hindi Phrase based on semantic similarity
90°step rotate button
स्क्रीन मोड चुनता है
90- स्टेप घुमाने का बटन
Here is an example where the model chooses an incorrect phrase. In this case, the default phrase (just based on splitting the manual text by period or comma) is the correct translation.
BAD:
English Phrase
Hindi Phrase by Default
Hindi Phrase based on semantic similarity
Controls electron beam scanning direction to rotate image
नियंत्रक ने छवि घुमाने के लिए स्कैनिंग दिशा खींचा
मोड बटन स्कैन किया जा रहा है
No current generalized conclusion on when the model errs.
Ways to check if the training data is correct are needed. We can back translate and check similarity with the English phrase based on meaning or based on character-level comparison, like Levenshtein distance. There is nothing interesting about that method.
Another problem is that creating the vector embedding is time consuming. I think it took 20 minutes to create vector embeddings for 10k phrases without a GPU, that’s about 10 phrases per second. It’s okay for non-real time applications.
There are two minor considerations in creating training data, which I haven’t tested.
- If you scrape two newspapers, and choose the phrases that are most semantically similar as pairs, it can still lead to errors because this just means they are more similar to each other than any other phrase, but not necessarily correct translations of each other.
- To solve #1, we can set a threshold on the dot product (>0.9). It’s possible that the threshold needs to be normalized by the length of a phrase. Does it? Maybe not because the embeddings are normalized before taking the dot product for this to work.
- If you add a new phrase to your vector database, do all the embeddings have to be normalized again?
The format of data used in fine-tuning LLMs for chat is different. Semantic similarity is still important since people could ask the same question in different ways (an obvious thought). How to creatively and effectively create that data?
Two other notes:
- Can a different representation (not a vector) capture information well? What kinds of math operations lend themselves to this representation? Since it’s been proven that a vector representation is effective, this line of thought is not very original, but still interesting to me. A more original line of thought would also be welcome.
- This pipeline is using Model 1 to create training data, Model 2 to translate. Model 1 results feed into Model 2. Model 2 results can feed into Model 1. I think this iteration works (and isn’t incestuous) because it’s similar to us learning from context clues. This was suggested in some paper and I have not tested it. Very powerful though.
I saw the sky gets paired with मैंने आकाश देखा
Even if Model 1 doesn’t know ‘sky’, pairs it because of other similar words. Needed for physical sciences / mechanical engineering vocabulary.
Trains model 2 on it. Now model 2 translates sky correctly in some other corpus. Model 1 scrapes and aligns that corpus. Model 1 sees new words in context with words it knows.
The models would only improve iteratively if they are exposed to new data, like the next chapter of a chemistry book, or if they generate data (which I guess is adversarial learning).
Script for Creating an Embedding:
# Example: Generating an embedding for a sentence using a transformer model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentence = "The cat sat on the mat."
embedding = model.encode(sentence) # Embedding output is a high-dimensional vector
print(embedding) # Output: e.g., array([0.23, -0.11, 0.75, ...]) of size 384These embeddings, aka vectors, aka list of numbers, get stored in a database.