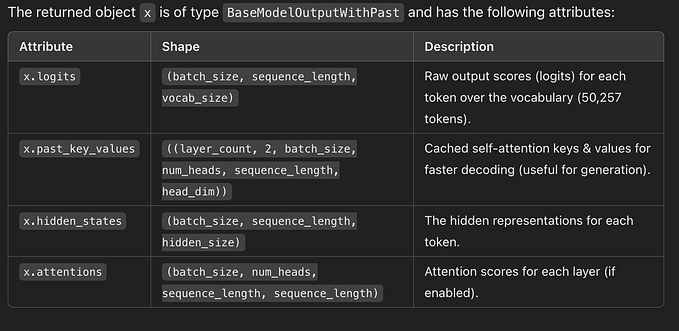
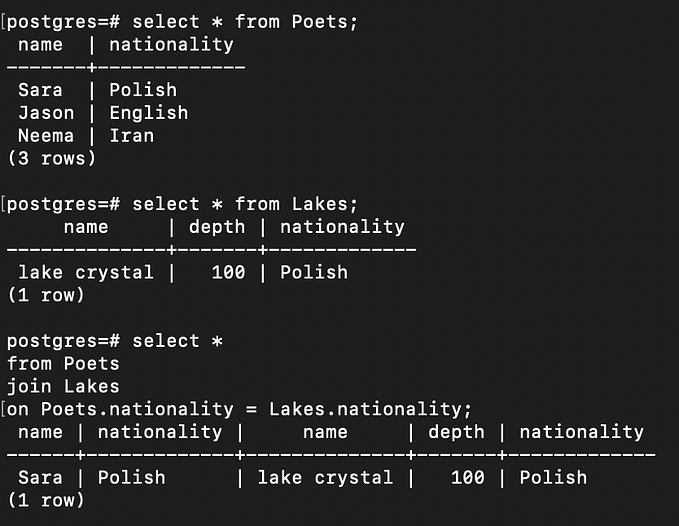
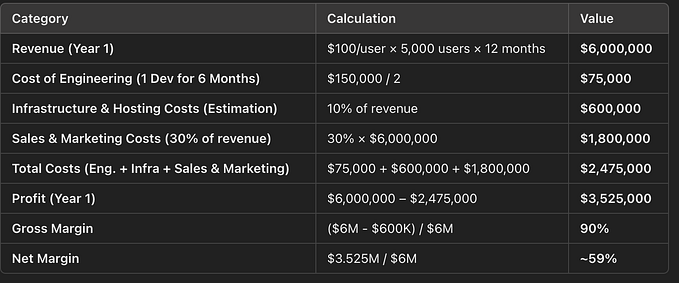
Finding the best model for a use case
The best for model for your usecase is the
- trained on data closest to yours
2. trained for the same objective as yours
3. trained well (not overfit etc)
2 and 3 are easier to check
Possible algorithms for #1) (?)
how to compare the distance between your data and a dataset (L1/L2 norm)
how to do it fast
data distributions can be compared
how is data distribution defined for an image set?
for numerical dataset? defining it with range is too simple. Has to be some other characs, like this is radio data, so text description of data
how to programatically find the model(s) trained on datasets that includes your data
Deep Learning Notes (esp from demucs paper)
- Any signal can be created if enough channels are used and with a transposed convolution (what does it mean, a transposed convolution?)
- One method is 1) take a coarse representation, 2) upsample, 3) compare it with the fine representation. This is done in a reference work.
Installing on vm
“/etc/apt/sources.list.d/kubernetes.list” [readonly] 1L, 114B
→
“deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /”
vm-6 created via multipass doesn’t have the kubernetes.list file
sudo apt install python3-venv
python3 -m venv bot_env
source bot_env/bin/activate
pip install pyyaml
Collecting pyyaml
Using cached PyYAML-6.0.2-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.metadata (2.1 kB)
Downloading PyYAML-6.0.2-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (739 kB)
739.2/739.2 kB 858.8 kB/s eta 0:00:00
Installing collected packages: pyyaml
Successfully installed pyyaml-6.0.2
separately maintaining requirements.txt may be best
pip install rasa_sdk — no-deps